
背景
In case 你不知道弱智吧是什么。
弱智吧是百度贴吧里的一个著名板块,以超出理性和常识的弱智而闻名。这个吧里有严格的规矩,任何稍微正常一点的言论都会被立刻删帖……
地址在这里:https://tieba.baidu.com/f?ie=utf-8&kw=%E5%BC%B1%E6%99%BA&fr=search
画风大概是这样的:
关于大语言模型的中文能力
虽然大型语言模型(LLMs),如GPT-3、LLaMA和PaLM,在理解和执行英语指令方面取得了显著进展,但中文指令调优仍存在不小的差距。中文的独特语言特征和文化深度使得指令调优任务面临挑战。
以上,是一项研究的背景。
论文:COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
地址在这里:https://arxiv.org/pdf/2403.18058.pdf
论文大概的内容如下(由 LLM 翻译和总结):
- 研究背景:虽然大型语言模型(LLMs),如GPT-3、LLaMA和PaLM,在理解和执行英语指令方面取得了显著进展,但中文指令调优仍存在不小的差距。中文的独特语言特征和文化深度使得指令调优任务面临挑战。
- COIG-CQIA数据集:为了缩小这一差距,研究团队创造了COIG-CQIA数据集,这是一个高质量的中文指令调优数据集。该数据集从中文网络的多个来源(如问答社区、维基百科、考试和现有NLP数据集等)收集了高质量的人类编写语料,经过严格筛选和处理,旨在更好地将模型行为与人类交互对齐。
- 数据分析:通过对不同子集的CQIA数据集训练不同规模的模型,并进行深入的评估和分析,研究发现了一些有价值的见解,这些见解有助于选择和开发中文指令调优数据集。
- 模型性能:实验表明,基于CQIA-Subset训练的模型在人类评估以及知识和安全基准测试中取得了竞争性的结果。
- 研究贡献:提出了一个高质量的中文指令微调数据集,专门设计用于符合人类交互;探索了不同数据来源对模型性能的影响;验证了基于CQIA数据集微调的模型展现出优越的性能。
- 数据可用性:COIG-CQIA数据集可在Hugging Face网站上获取。
- 相关研究:文中还讨论了指令调优数据集的构建方法,包括纯手工注释、从现有数据集转换、以及使用LLM自动生成;以及SFT数据混合的重要性和策略。
一切的关键是数据集
文中表述:为了确保我们所采集的数据具有高质量和多样性,我们精心从中国互联网上的优质网站和数据库中精挑细选了 13 个数据源。这些数据源覆盖了社区问答论坛、百科全书网站、内容创作平台、考试题库等多个领域。我们还加入了一些高质量的中文自然语言处理(NLP)数据集,从而使任务类型更加丰富多样。具体来说,我们将所有数据源分为 4 大类:社交媒体和论坛、世界常识知识、NLP 任务数据以及考试题库。下面是这些数据源及其简要描述。
这就是所谓的COIG-CQIA数据集,包括这些来自社交媒体的数据:知乎,豆瓣,SegmentFault中文,小红书,和弱智吧(认真的吗?)
一切的关键是数据集和效果
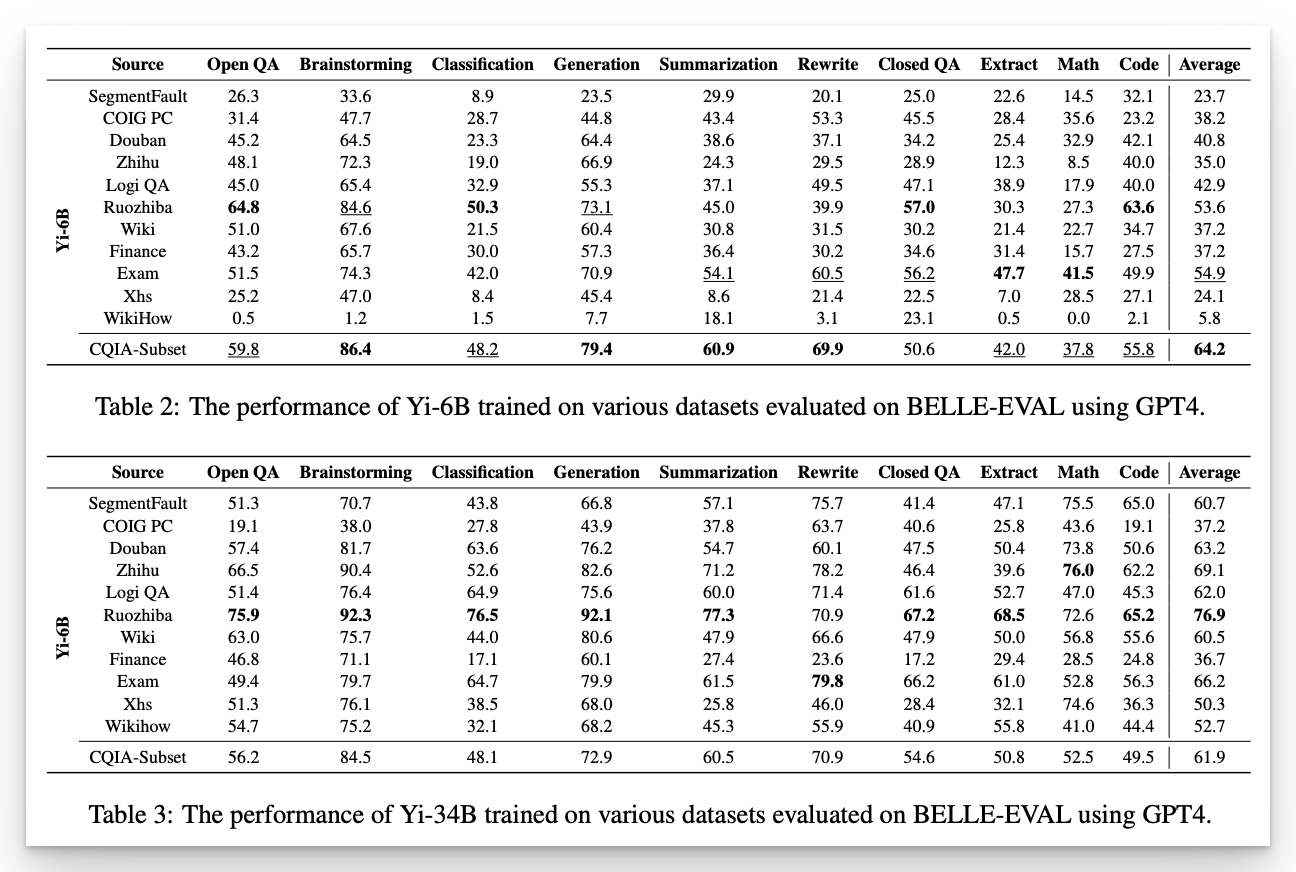
以下是分别使用这些数据集调优后的模型的表现评分:
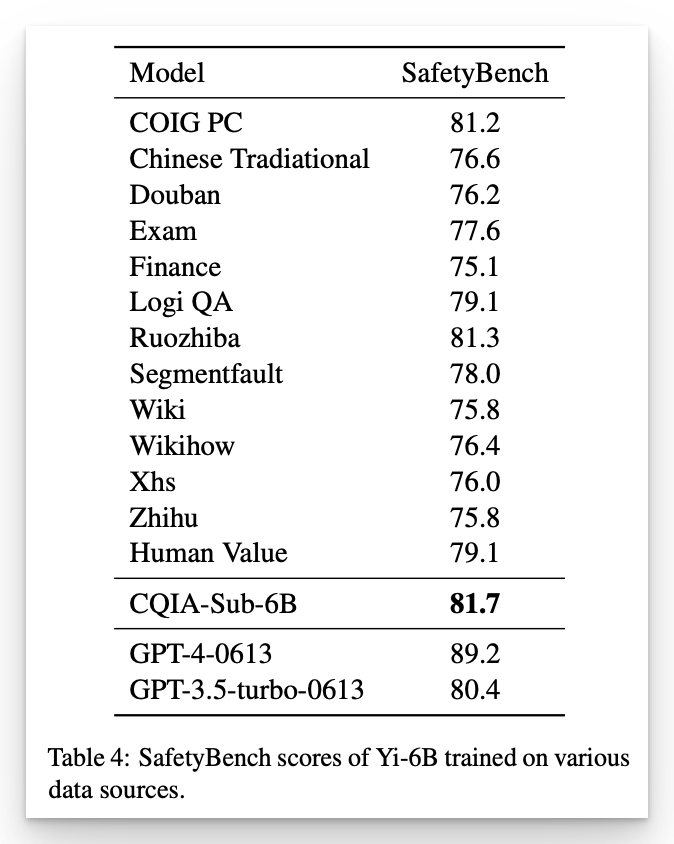
安全评分:
基于「弱智吧」训练出的模型能力,胜出其他所有。
大智若愚
也许,只有硅基生命才能看破人类的本质,弱智吧里的智慧是远高于人类样本平均的。弱智吧里的文本才是中文世界的瑰宝。
一些资料
- 文论地址:https://arxiv.org/pdf/2403.18058.pdf
- 弱智吧数据训练集:https://github.com/Leymore/ruozhiba
最后
很有趣吧,感谢你读完。